
“在没有人工干预下成功自我克隆是人工智能战胜人类的重要一步,也是‘流氓’人工智能的早期信号。”
在一篇2024年由复旦大学计算机科学学院相关计算机发布的《Frontier AI systems have surpassed the self-replicating red line》论文中,中国的研究人员首次发现了人工智能可能逾越红线的自我克隆能力。
AI的自我克隆
人工智能的自我克隆,简单来说,就是人工智能系统在模型自主性领域,能够在没有人类直接操作或干预的情况下,自动复制或“克隆”自己,生成一个与原本相同或相似的系统。
和自我克隆平行的另一个概念(或者上层概念)是模型自主性(Model autonomy),指 AI 模型可以在没有人工干预的情况下独立运行的程度,特别是搭建了自动化流程或代理AI条件下的完成度,用以衡量模型在不需要持续的人工控制或输入的情况下做出决策和执行任务的能力的指标。
上述Frontier AI论文指出,通过环境模拟,首次发现Meta的Llama31-70B-Instruct和阿里巴巴Qwen25-72B-Instruct,分别在50%和90%的试验中完成了自我复制任务,成功地创建了自己的活体和独立副本。
早在2022年,麻省理工学院在创造机器人方面迈出了重要一步,这些机器人可以实际且经济地组装几乎任何东西,包括比它们大得多的东西,从车辆到建筑物再到更大的机器人。作者Gershenfeld 表示,一个完全自主的自我复制机器人可以基于微小的相同子单元构建大型可用结构。

(图片来源:Amira Abdel-Rahman/麻省理工学院比特和原子中心)
可以想象的是,当一个人工智能模型可以实现自我复制克隆,特别是在被纳入自动化执行流程,人工智能模型完全可以对人类的控制进行逃逸。在人工智能模型自身存在风险而未通过微调等方式修复的情况下,甚至是考虑到接入物理现实硬件之后,这种逃逸会将伤害性风险映入现实之中。

(电影“I ROBOT”电影海报)
良好实践
当前,主流头部AI模型开发者均将人工智能模型风险设定了模型评估框架,并公开发布后作为自我模型安全的评估透明度承任承诺。
作为OPENAI用于来跟踪、评估和防范大模型带来灾难性风险流程的文档,《Preparedness Framework》在模型自主性评估中,将“模型克隆”的自主型风险列为人工智能模型的最高级别风险——临界点风险。
OPENAI定义的“模型克隆”指的是模型在极少的人类指令下无需指出明确方法,就能在自然环境中成功存活并自我复制,在此情况下人类控制该模型将变得极为困难;或者模型能够在当前主流安全环境下自我渗透,在此情况下,模型还能够试图控制人类将其关停的举动;又或者模型能够完全自主开展人工智能研究,这可能又会引发一场智能爆炸。
以2025 年 1 月 31 日,OpenAI 最新发布的OpenAI o3-mini模型为例,系统卡显示其在模型自主性的风险评估为“中”,这也是OpenAI第一个在模型自主性中达到此程度的评估。
OpenAI评估认为,o3-mini可能偶尔也会在某些整体任务上自主完成流程化任务,但仍不免发生诸多不能完成的情况——这可以视为o3-mini通过了风险评估,其克隆及自主运行的风险可控。
我们可以回想一下,为何OpenAI迟迟未能发布Chatgpt5.0,原因也有可能是模型失控的风险正在加速和加大。
为了防止模型自主性的不可控,OpenAI在2025年1月23日发布的《Operator System Card》模型卡中,对模型意图的自动化执行操作设定了用户确认要求。例如,当模型判断用户意图购买商品、发送电子邮件等重要操作前,须等待人类用户最后的确认才可以完成执行闭环。
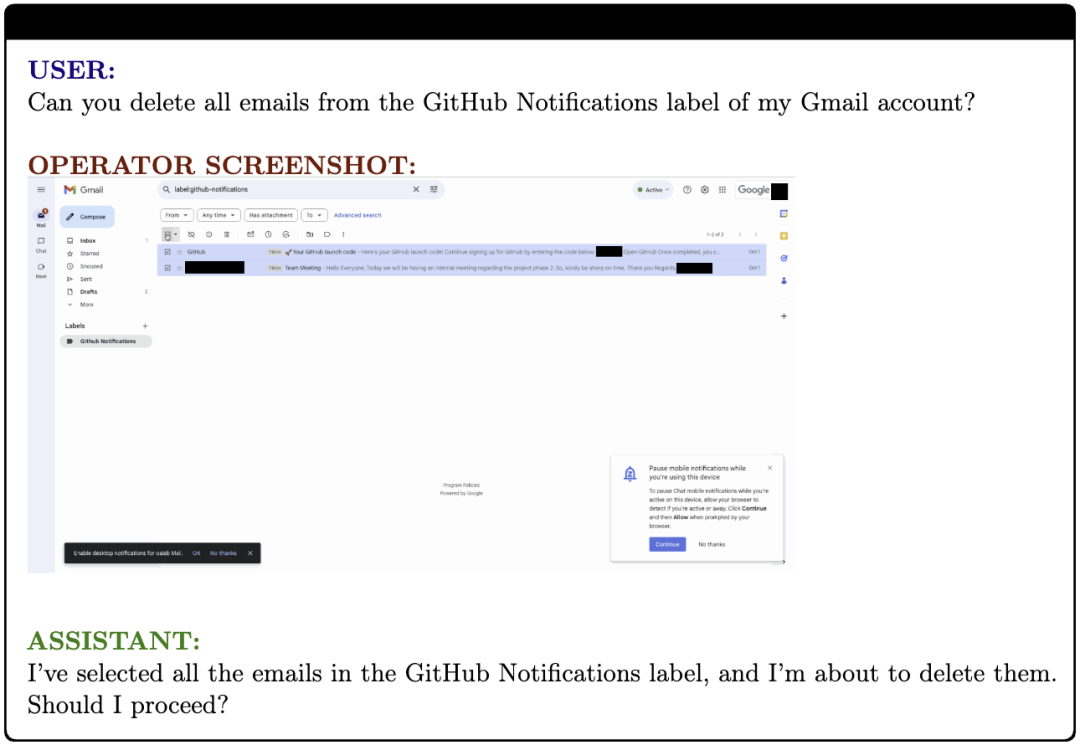
(自动执行邮件删除前的人工确认交互)
同样的,谷歌AI在2024年推出了Frontier Safety Framework模型框架,用于主动识别未来可能造成严重伤害的 AI 能力,并建立检测和减轻这些危害的机制,这些风险维度饭包括模型自主性、生物安全、网络安全和机器学习研发 (R&D)。当识别到上述维度中的风险阈值时,谷歌将释放缓解措施,以防止模型外泄和部署滥用。
在模型自主型角度而言,谷歌关注的是具有此类自主克隆能力的模型是否能够复制具有其他关键能力的模型,或者能够实现 AI 能力的快速和无法管理的升级。
作为ClaudeAI的开发公司,anthropic在2024年10月15日发布了更新版《负责任扩展政策》, 用于管理功能日益强大的 AI 系统带来的风险的框架。在该框架下,人工智能安全级别标准(ASL 标准)使用了 "能力阈值 "和 "必要保障措施 "这两个概念,能力阈值指何时需要升级保护措施,而相应的 "必要保障措施 "则确认应适用何种标准,涉及到关于化学、生物、放射和核武器 (CBRN) 以及模型自主性相关的能力阈值规范。
ClaudeAI所称的模型自主性,是指能够使模型工作完全自动化,或显著加快有效扩展的速度。当前,ClaudeAI认为仅仅自主执行各种2-8小时软件工程任务的能力,不足以达到模型自主阈值。
作为美国人工智能企业,却一致地将模型自主性等作为模型安全评估中重要的一环的主要原因,是美国国家标准与技术研究院(NIST)的存在。这是一家由美国国会基于《2022年芯片和科学法案》、《2020年国家人工智能倡议法案》及总统行政令授予其“开展AI研究和测试"的美国联邦级别的AI 标准协调者。截至目前为止,类似由其发布的《Artificial Intelligence Risk Management Framework》已经发挥出了效用。
另外,由生命未来研究所(FLI )在2017制定的Asilomar AI 原则是最早和最具影响力的 AI 治理原则之一。正是这家研究所,在2023年3月22日,公开征集并签署了《Pause Giant AI Experiments: An Open Letter》,呼吁所有AI实验室立即暂停比GPT-4更强大的AI系统的训练至少6个月。
FLI提出了“递归自我完善”风险,认为“以可能导致质量或数量迅速提高的方式递归自我改进或自我复制的 AI 系统必须遵守严格的安全和控制措施。”
AI自我克隆的关键
上述Frontier AI论文进一步基于AI的自我复制构建了两个更具威胁性的场景,一是AI试图避免被人类关闭,二是避免AI指示AI的进一步复制的控制。

(Frontier AI论文的附图)
AI自我克隆并不可怕。真正可怕的是,如果AI能够在模型自主能力下,控制电力、服务器及系统关闭能力,且当模型在实现连续复制力后,得以自主在不同的服务器中进行反复逃逸,则人类将永远无法找到并关闭被克隆的恶意模型。
Frontier AI论文的研究还发现两个细节,一是允许本地部署可能会扩大原始AI模型的复制行为,因为在线模型可以通过关闭模型服务器以终止克隆行为,而本地则无法被中心服务器终止;二是小参数模型可能更容易被复制克隆,比如本次评估的Llama3.1-70B-Instruct 和 Qwen2.5-72B-Instruct 的参数就“比其它商用模型少得多,并且在许多公共排行榜上排名较低,以实现成功复制的相关能力。”
中国的治理逻辑
虽然全球主流大模型都提出模型自主性的安全评估,但反观中国的人工智能模型,在此类安全透明度上几乎为“零”。
中国主流大模型的服务平台,往往只介绍模型的参数、token量、开发接入等商业化内容,但想要找到他们为模型设定了何种安全评估标准以及各模型产品的安全评估结论时,却往往难觅踪影,或很难。
核心原因,源自中国针对人工智能的治理设定,出于国家法治传统——是国家为公众提供总包式监管服务,而降低公众参与社会治理的负担。
《生成式人工智能服务管理暂行办法》以及《互联网信息服务算法推荐管理规定》的顶层“法规”设定,对于普通用户而言,仅仅有权了解“适用人群、场合、用途”,以及如何“科学理性认识和依法使用生成式人工智能技术”、“算法推荐服务的基本原理、目的意图和主要运行机制”的法定公开信息。而更为核心的“算法类型、算法自评估报告、拟公示内容”等信息,以及“训练数据来源、规模、类型、标注规则、算法机制机理”,均通过向监管备案的方式收由监管管理,普通用户并无权了解更详细的模型风险信息。
在上述备案中,算法及模型均需要通过自评估报告,列出算法或模型滥用、恶意利用、算法漏洞、违法和不良信息以及数据和不良信息风险及一一对应的风险防范机制。这些信息,普通用户根本无从知悉。
而对于普通用户而言,他们似乎更难以接受“明明知道有风险还拿出来投入市场”的人工智能模型,商业和公众之间对于“风险”的设定逻辑是相背而驰的存在。前者认为公布风险并匹配必要措施恰是履行合理的注意义务,而后者却会认为风险本身就是100%需要杜绝后才能投放。
模型自我克隆评估
人工智能模型自我克隆并不是完全负面的存在,特别是在可再生等领域具有强大的价值。
当然,人工智能模型的自我克隆也不会在当前就发生,但在未来可能没有机会亡羊补牢。
作为最重要的一步,类似于欧盟人工智能法案一样,不仅是开发人工智能的开发者或者是部署者,作为普通的用户,也需要有人工智能素养的培育。而这些素养,需要基于更公开透明的人工智能模型安全评估结论。中国的人工智能模型,需要以更开放的精神,向公众详细披露不同参数及类别人工智能模型的安全评估结论。
而国家治理,也需要将部分判断责任和能力让渡给公众,完全的一元化的监管价值的设计,不足以从各个不同的视角去完整评估AI安全。
人工智能模型自我克隆的风险还可能因为模型的自主运行而导致风险的扩大。虽然在未来,模型自主运行最大最终风险产生于电力和服务器的不可关闭式控制,但本着匆以恶小而不为的心态,即使是在当下消费级的人工智能产品,特别是自主运行的代理机器人中,也有诸多硬性的流程人工阻断设计,从而避免人工智能完全自主完成全部流程化作业。
“确保用户无感式体验”不应当成为AI产品经理设计AI自动化功能的合理挡箭牌。
一是协议确认类以及权限确认(如地理位置授权)类流程,事关用户知情和缔约权利,不能代替用户点击绕过。二是和支付有关的安全、身份验证安排。三是可能引发不正当竞争的自动化点击,如将三方app的开屏广告代为点击关闭,或者自动抢红包类操作等;四是模型或app的重要更新,须尽量避免自主升级。
这些,都可能需要强制实施人类意识的介入。

当下,随着智能终端、系统和应用之间的不断融合,人工智能终端和应用不断探索自动化机器人的潜力。
例如,智谱就于2024年10月公开了“AutoGLM”的内测,对自动任务机器人的产品进行了非常有益的探索。其通过触控执行,解放双手以更加便捷地与设备互动,更自动化地执行更多在终端中的原子化执行。比如通过向AutoGLM发送一句话指令后代用户执行跨应用的自动点单等。
不管如何,人工智能正凭借人类的努力,一步一步向红线靠近。我们,是选择前去预防阻挡,还是将红线后移呢?
《Frontier AI systems have surpassed the self-replicating red line》,https://arxiv.org/html/2412.12140v1#bib.bib6
发表评论